Java より native の方が遅いってどういうこっちゃねん - 技術編
環境1 - メインマシン
| CPU | Athlon 64 x2 4400+ |
|---|---|
| Mem | 6GB - DDR2 800 DualChannel |
| OS | WinXP x64 SP2 |
| Java | 1.6.0_07 32bit版 |
cpp - native コード
Visual Studio 2003 でビルド
- cl
- /O2 /GL /D "WIN32" /D "NDEBUG" /D "_CONSOLE" /D "_UNICODE" /D "UNICODE" /FD /EHsc /MD /GS /Yu"stdafx.h" /Fp"Release/Bench.pch" /Fo"Release/" /Fd"Release/vc70.pdb" /W3 /nologo /c /Wp64 /Zd /TP
- link
- /OUT:"Release/Bench.exe" /INCREMENTAL:NO /NOLOGO /DEBUG /PDB:"Release/Bench.pdb" /SUBSYSTEM:CONSOLE /OPT:REF /OPT:ICF /LTCG /MACHINE:X86
// Bench.cpp #include "stdafx.h" class Bench { public: Bench(int nID) : m_nRand(::timeGetTime()) , m_nID(nID) , m_nResult(::timeGetTime()){} ~Bench(){} void Run() { DWORD dateStart = ::timeGetTime(); _tprintf(_T("thread %d start...\n"), m_nID); std::vector<int> anArray(ARRAY_SIZE); for(int n = 0; n < TIMES; ++n) { for(int a = 0; a < ARRAY_SIZE; ++a) { int r1 = my_rand(); int r2 = my_rand(); int r3 = my_rand(); int r4 = my_rand(); // 適当に演算 anArray[a] += ((r1 + r2 * r4) | (r3 >> (r4 & 0x06))) ^ r1; anArray[a] &= 0x7fffffff; } } // 何の結果かわからないけど、結果算出 for(int i = 0; i < ARRAY_SIZE; ++i) { m_nResult += anArray[i]; } DWORD dateEnd = ::timeGetTime(); _tprintf(_T("thread %d end / %d ms\n"), m_nID, dateEnd - dateStart); } int GetResult() { return m_nResult; } private: int my_rand() { return m_nRand = ((m_nRand * 0x654321) | (m_nRand << 16) ^ (m_nRand >> 7)) & 0x7fffffff; } private: int m_nRand; int m_nID; int m_nResult; static const int TIMES = 0x8000; static const int ARRAY_SIZE = 100000; }; unsigned int CALLBACK ThreadStart(void* pVoid) { Bench b((int)(INT_PTR)pVoid); b.Run(); return b.GetResult(); } int _tmain(int argc, _TCHAR* argv[]) { ::timeBeginPeriod(1); int nCount = _ttoi(argv[1]); std::vector<HANDLE> stlHandle(nCount); for(int i = 0; i < nCount; ++i) { unsigned int threadID = 0; stlHandle[i] = (HANDLE)_beginthreadex(NULL, 0, &ThreadStart, (void*)(INT_PTR)i, CREATE_SUSPENDED, &threadID); } DWORD dwBegin = ::timeGetTime(); for(int i = 0; i < nCount; ++i) { ::ResumeThread(stlHandle[i]); } ::WaitForMultipleObjects(nCount, &stlHandle[0], true, INFINITE); DWORD dwEnd = ::timeGetTime(); _tprintf(_T("# %dms\n"), dwEnd - dwBegin); for(int i = 0; i < nCount; ++i) { ::CloseHandle(stlHandle[i]); } ::timeEndPeriod(1); return 0; }
// stdafx.h #include <windows.h> #include <process.h> #include <iostream> #include <tchar.h> #include <vector> #include <string.h> #include <mmsystem.h> #pragma comment(lib, "winmm.lib")
Java コード - 前回と一緒
import java.util.Date; public class Bench extends Thread { static final int TIMES = 0x8000; static final int ARRAY_SIZE = 100000; int m_nRand; int m_nResult; int m_nID; public Bench(int nID) { m_nID = nID; m_nRand = (int)(Math.random() * 0x1000); } private int rand() { // えせ乱数 return m_nRand = ((m_nRand * 0x654321) | (m_nRand << 16) ^ (m_nRand >> 7)) & 0x7fffffff; } public void run() { Date dateStart = new Date(); System.out.println("thread " + m_nID + " start..."); int[] anArray = new int[ARRAY_SIZE]; for(int n = 0; n < TIMES; ++n) { for(int a = 0; a < ARRAY_SIZE; ++a) { int r1 = rand(); int r2 = rand(); int r3 = rand(); int r4 = rand(); // 適当に演算 anArray[a] += ((r1 + r2 * r4) | (r3 >> (r4 & 0x06))) ^ r1; anArray[a] &= 0x7fffffff; } } // 何の結果かわからないけど、結果算出 for(int i = 0; i < ARRAY_SIZE; ++i) { m_nResult += anArray[i]; } Date dataEnd = new Date(); System.out.println("thread " + m_nID + " end / " + (dataEnd.getTime() - dateStart.getTime()) + "ms"); } public static void main(String[] str) { int nThreadCount = Integer.parseInt(str[0]); Bench[] anTests = new Bench[nThreadCount]; for(int i = 0; i < nThreadCount; ++i) anTests[i] = new Bench(i); Date pcStart = new Date(); for(int i = 0; i < nThreadCount; ++i) anTests[i].start(); for(int i = 0; i < nThreadCount; ++i) { try { anTests[i].join(); // コレはひどい } catch(InterruptedException e) {} } Date pcEnd = new Date(); System.out.println((pcEnd.getTime() - pcStart.getTime()) + "ms"); } };
実行結果
| スレッド数→ | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| Athlon 64 x2 4400+ / Java | 58946.8 | 60021.8 | 89898.6 | 119137.5 | 148559.2 | 177933.1 | 207727.8 | 236882.9 |
| Athlon 64 x2 4400+ / exe | 51185.5 | 51623.1 | 76977.6 | 101638.6 | 127087.1 | 151785.5 | 177005.7 | 201633.9 |
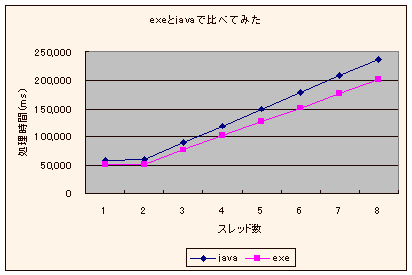
↑Athlon 64 x2 4400+ で、javaとexeの実行時間比較
| スレッド数→ | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| Athlon XP 1500+ / Java | 125427.2 | 250257.6 | 373717.1 | 495440.6 | 619389.1 | 743142.2 | 864845.3 | 988209.5 |
| Athlon XP 1500+ / exe | 109388.5 | 218241.9 | 326402.9 | 435133.9 | 544283.9 | 654202.8 | 760538.6 | 869151 |
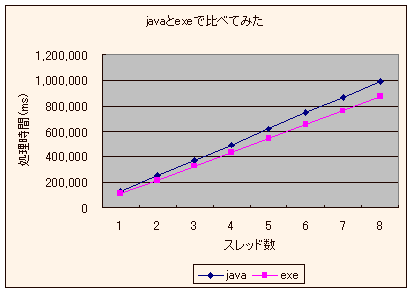
↑Athlon XP 1500+ で、javaとexeの実行時間比較
| スレッド数→ | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| Atom 330 / Java | 55781 | 58629.5 | 66132.8 | 72808.1 | 101604.5 | 109785.9 | 130402.9 | 147034.5 |
| Atom 330 / exe | 122135.5 | 142766.8 | 145396.4 | 159807.4 | 228494.9 | 241398 | 288904.1 | 326393.5 |
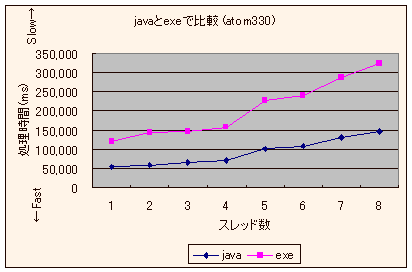
いやまぁ、Java と VC じゃー正確な比較なんて出来るわけがないのは分かるのですが、それでも Athlon系で Native が早いのであれば、ATOMでも Native が早いだろうと期待していまいます。
ってか、Javaもどこかしらで Native に変換している以上、"JavaVM" というレイヤーが存在する Javaの方が遅くような気がしちゃうわけですが…
しかし、今回はそれが大きく違った…… なぁぜぇだぁ…
気になること - VCの最適化
処理の要となるのは「Run()内の for(ARRAY_SIZE)内」になるわけですが、VCでここのコードがどのように吐かれているのか調べて見たところ、次のようになっていました。(アンループ化されていますね)
for(int a = 0; a < ARRAY_SIZE; ++a) 00401050 mov eax,dword ptr [esp+1Ch] 00401054 add eax,8 00401057 mov dword ptr [esp+0Ch],4E20h 0040105F nop { int r1 = my_rand(); 00401060 mov ecx,dword ptr [ebx] 00401062 mov edi,ecx 00401064 mov edx,ecx 00401066 imul ecx,ecx,654321h 0040106C sar edx,7 0040106F shl edi,10h 00401072 xor edi,edx 00401074 or edi,ecx 00401076 and edi,7FFFFFFFh int r2 = my_rand(); 0040107C mov edx,edi 0040107E imul edx,edx,654321h 00401084 mov ebp,edi 00401086 shl ebp,10h 00401089 mov ecx,edi 0040108B sar ecx,7 0040108E xor ebp,ecx 00401090 or ebp,edx 00401092 and ebp,7FFFFFFFh int r3 = my_rand(); 00401098 mov edx,ebp 0040109A shl edx,10h 0040109D mov ecx,ebp 0040109F sar ecx,7 004010A2 xor edx,ecx 004010A4 mov ecx,ebp 004010A6 imul ecx,ecx,654321h 004010AC or edx,ecx 004010AE and edx,7FFFFFFFh int r4 = my_rand(); 004010B4 mov esi,edx 004010B6 mov ecx,edx 004010B8 sar ecx,7 004010BB shl esi,10h 004010BE xor esi,ecx 004010C0 mov ecx,edx 004010C2 imul ecx,ecx,654321h 004010C8 or esi,ecx 004010CA and esi,7FFFFFFFh 004010D0 mov dword ptr [ebx],esi // 適当に演算 anArray[a] += ((r1 + r2 * r4) | (r3 >> (r4 & 0x06))) ^ r1; 004010D2 mov ecx,esi 004010D4 imul esi,ebp 004010D7 and ecx,6 004010DA sar edx,cl 004010DC add esi,edi 004010DE or edx,esi 004010E0 mov esi,dword ptr [eax-8] 004010E3 xor edx,edi 004010E5 add esi,edx anArray[a] &= 0x7fffffff; 004010E7 mov ecx,esi 004010E9 and ecx,7FFFFFFFh 004010EF mov dword ptr [eax-8],esi 004010F2 mov dword ptr [eax-8],ecx 004010F5 mov ecx,dword ptr [ebx] ; アンループ1回目 004010F7 mov edi,ecx 004010F9 mov edx,ecx 004010FB imul ecx,ecx,654321h 00401101 sar edx,7 00401104 shl edi,10h 00401107 xor edi,edx 00401109 or edi,ecx 0040110B and edi,7FFFFFFFh 00401111 mov edx,edi 00401113 imul edx,edx,654321h 00401119 mov ebp,edi 0040111B shl ebp,10h 0040111E mov ecx,edi 00401120 sar ecx,7 00401123 xor ebp,ecx 00401125 or ebp,edx 00401127 and ebp,7FFFFFFFh 0040112D mov edx,ebp 0040112F shl edx,10h 00401132 mov ecx,ebp 00401134 sar ecx,7 00401137 xor edx,ecx 00401139 mov ecx,ebp 0040113B imul ecx,ecx,654321h 00401141 or edx,ecx 00401143 and edx,7FFFFFFFh 00401149 mov esi,edx 0040114B mov ecx,edx 0040114D shl esi,10h 00401150 sar ecx,7 00401153 xor esi,ecx 00401155 mov ecx,edx 00401157 imul ecx,ecx,654321h 0040115D or esi,ecx 0040115F and esi,7FFFFFFFh 00401165 mov dword ptr [ebx],esi 00401167 mov ecx,esi 00401169 imul esi,ebp 0040116C and ecx,6 0040116F sar edx,cl 00401171 add esi,edi 00401173 or edx,esi 00401175 mov esi,dword ptr [eax-4] 00401178 xor edx,edi 0040117A add esi,edx 0040117C mov dword ptr [eax-4],esi 0040117F mov ecx,esi 00401181 and ecx,7FFFFFFFh 00401187 mov dword ptr [eax-4],ecx 0040118A mov ecx,dword ptr [ebx] ; アンループ2回目 0040118C mov edi,ecx 0040118E mov edx,ecx 00401190 imul ecx,ecx,654321h 00401196 sar edx,7 00401199 shl edi,10h 0040119C xor edi,edx 0040119E or edi,ecx 004011A0 and edi,7FFFFFFFh 004011A6 mov edx,edi 004011A8 imul edx,edx,654321h 004011AE mov ebp,edi 004011B0 mov ecx,edi 004011B2 sar ecx,7 004011B5 shl ebp,10h 004011B8 xor ebp,ecx 004011BA or ebp,edx 004011BC and ebp,7FFFFFFFh 004011C2 mov edx,ebp 004011C4 shl edx,10h 004011C7 mov ecx,ebp 004011C9 sar ecx,7 004011CC xor edx,ecx 004011CE mov ecx,ebp 004011D0 imul ecx,ecx,654321h 004011D6 or edx,ecx 004011D8 and edx,7FFFFFFFh 004011DE mov esi,edx 004011E0 shl esi,10h 004011E3 mov ecx,edx 004011E5 sar ecx,7 004011E8 xor esi,ecx 004011EA mov ecx,edx 004011EC imul ecx,ecx,654321h 004011F2 or esi,ecx 004011F4 and esi,7FFFFFFFh 004011FA mov dword ptr [ebx],esi 004011FC mov ecx,esi 004011FE imul esi,ebp 00401201 and ecx,6 00401204 sar edx,cl 00401206 add esi,edi 00401208 or edx,esi 0040120A mov esi,dword ptr [eax] 0040120C xor edx,edi 0040120E add esi,edx 00401210 mov ecx,esi 00401212 and ecx,7FFFFFFFh 00401218 mov dword ptr [eax],esi 0040121A mov dword ptr [eax],ecx 0040121C mov ecx,dword ptr [ebx] ; アンループ3回目 0040121E mov edi,ecx 00401220 mov edx,ecx 00401222 imul ecx,ecx,654321h 00401228 shl edi,10h 0040122B sar edx,7 0040122E xor edi,edx 00401230 or edi,ecx 00401232 and edi,7FFFFFFFh 00401238 mov ebp,edi 0040123A shl ebp,10h 0040123D mov ecx,edi 0040123F sar ecx,7 00401242 xor ebp,ecx 00401244 mov edx,edi 00401246 imul edx,edx,654321h 0040124C or ebp,edx 0040124E and ebp,7FFFFFFFh 00401254 mov edx,ebp 00401256 shl edx,10h 00401259 mov ecx,ebp 0040125B sar ecx,7 0040125E xor edx,ecx 00401260 mov ecx,ebp 00401262 imul ecx,ecx,654321h 00401268 or edx,ecx 0040126A and edx,7FFFFFFFh 00401270 mov esi,edx 00401272 mov ecx,edx 00401274 sar ecx,7 00401277 shl esi,10h 0040127A xor esi,ecx 0040127C mov ecx,edx 0040127E imul ecx,ecx,654321h 00401284 or esi,ecx 00401286 and esi,7FFFFFFFh 0040128C mov dword ptr [ebx],esi 0040128E mov ecx,esi 00401290 imul esi,ebp 00401293 and ecx,6 00401296 sar edx,cl 00401298 add esi,edi 0040129A or edx,esi 0040129C mov esi,dword ptr [eax+4] 0040129F xor edx,edi 004012A1 add esi,edx 004012A3 mov ecx,esi 004012A5 and ecx,7FFFFFFFh 004012AB mov dword ptr [eax+4],esi 004012AE mov dword ptr [eax+4],ecx 004012B1 mov ecx,dword ptr [ebx] ; アンループ4回目 004012B3 mov edi,ecx 004012B5 mov edx,ecx 004012B7 imul ecx,ecx,654321h 004012BD sar edx,7 004012C0 shl edi,10h 004012C3 xor edi,edx 004012C5 or edi,ecx 004012C7 and edi,7FFFFFFFh 004012CD mov edx,edi 004012CF imul edx,edx,654321h 004012D5 mov ebp,edi 004012D7 shl ebp,10h 004012DA mov ecx,edi 004012DC sar ecx,7 004012DF xor ebp,ecx 004012E1 or ebp,edx 004012E3 and ebp,7FFFFFFFh 004012E9 mov edx,ebp 004012EB shl edx,10h 004012EE mov ecx,ebp 004012F0 sar ecx,7 004012F3 xor edx,ecx 004012F5 mov ecx,ebp 004012F7 imul ecx,ecx,654321h 004012FD or edx,ecx 004012FF and edx,7FFFFFFFh 00401305 mov esi,edx 00401307 shl esi,10h 0040130A mov ecx,edx 0040130C sar ecx,7 0040130F xor esi,ecx 00401311 mov ecx,edx 00401313 imul ecx,ecx,654321h 00401319 or esi,ecx 0040131B and esi,7FFFFFFFh 00401321 mov ecx,esi 00401323 mov dword ptr [ebx],esi 00401325 imul esi,ebp 00401328 and ecx,6 0040132B sar edx,cl 0040132D add esi,edi 0040132F or edx,esi 00401331 mov ecx,dword ptr [esp+0Ch] 00401335 xor edx,edi 00401337 mov edi,dword ptr [eax+8] 0040133A add edi,edx 0040133C mov esi,edi 0040133E and esi,7FFFFFFFh 00401344 mov dword ptr [eax+8],edi 00401347 mov dword ptr [eax+8],esi 0040134A add eax,14h 0040134D dec ecx 0040134E mov dword ptr [esp+0Ch],ecx 00401352 jne Bench::Run+60h (401060h) 00401358 dec dword ptr [esp+10h] 0040135C jne Bench::Run+50h (401050h) } }
このあたりのコードが「低速」な原因を作り出しているに違いないわけですが…さて、その低速理由は……? …うーん、よく分からない。
atomは「インオーダー」になった故に、命令を並列実行できる「ペアリング」が出来てないのかしら? と思ってみるも、それだったら Java もうまくペアリング出来ないハズなので、違う気も…。それとも JavaVMがクラスロード時になんか賢くなんかやってる…? うーん…
Native が怠る理由…うーん…。 今のおいらには、他の可能性が思いつかない……
ざんねん!! わたしの ぼうけんは ここで おわってしまった!!
誰か詳しく調べてください…… (他力本願
余談 - ペアリング具合を検証してみる
ペアリングはほとんど出来てない臭いです。にわか知識でどうなるか確認してみたのですが…… v の出番がほとんど無し。 atomは パイプラインが2つ あるとのことですが、片方のパイプラインはスカスカなんだろうなぁ、このコードは。(ぉ
# こういうコードの場合は、特にMultiThreadingが役に立つのだろう。多分。
0040105F nop { int r1 = my_rand(); 00401060 mov ecx,dword ptr [ebx] // u 00401062 mov edi,ecx // u - ecxがかぶる 00401064 mov edx,ecx // v 00401066 imul ecx,ecx,654321h // u 0040106C sar edx,7 // u 0040106F shl edi,10h // u - sarとペアになれない 00401072 xor edi,edx // u - ediがかぶる 00401074 or edi,ecx // u - ediがかぶる 00401076 and edi,7FFFFFFFh // u - ediがかぶる : : : anArray[a] += ((r1 + r2 * r4) | (r3 >> (r4 & 0x06))) ^ r1; 004010D2 mov ecx,esi 004010D4 imul esi,ebp // u 004010D7 and ecx,6 // u 004010DA sar edx,cl // u - ecx/clがかぶる 004010DC add esi,edi // v 004010DE or edx,esi // u 004010E0 mov esi,dword ptr [eax-8] // v? - esiが心配(何 004010E3 xor edx,edi // u 004010E5 add esi,edx // u - edxがかぶる anArray[a] &= 0x7fffffff; 004010E7 mov ecx,esi // u - esiがかぶる 004010E9 and ecx,7FFFFFFFh // u - ecxがかぶる 004010EF mov dword ptr [eax-8],esi // v 004010F2 mov dword ptr [eax-8],ecx // u
【参考にさせていただきました】