atomはやっぱりインオーダープロセッサだなぁと実感した
asm で「ペアリング出来てない」と「ペアリングしてる」コードを書いて、どんだけ差が出るのか確認してみました。
実行テスト環境
環境1 - メインマシン
| CPU | Athlon 64 x2 4400+ |
|---|---|
| Mem | 6GB - DDR2 800 DualChannel |
| OS | WinXP x64 SP2 |
コード
非ペアリング版
#include <stdio.h> #include <windows.h> #include <process.h> #include <tchar.h> #include <mmsystem.h> #pragma comment(lib, "winmm.lib") static const int TIMES = 0x20000000; unsigned int CALLBACK ThreadFunc(void* v) { int id = (int)(INT_PTR)v; int a = 10; int b = 20; DWORD dwBegin = ::timeGetTime(); __asm { mov eax, a ; mov edx, b ; mov ecx, TIMES ; カウンタ変数 _LOOP: ;↓ すごくペアリング出来てない - ってか何もしてねぇ(ぉ mov esi, eax ; a xor esi, esi ; b mov esi, eax ; c mov eax, esi ; d mov edi, edx ; a' xor edi, edi ; b' mov edi, edx ; c' mov edx, edi ; d' loop _LOOP; } DWORD dwEnd = ::timeGetTime(); printf("%d - %dms \n", id, dwEnd - dwBegin); return 0; } int _tmain(int arcv, TCHAR* argv[]) { ::timeBeginPeriod(1); int nCount = _ttoi(argv[1]); HANDLE* aHandle = new HANDLE[nCount]; for(int i = 0; i < nCount; ++i) { unsigned int threadID = 0; aHandle[i] = (HANDLE)_beginthreadex(NULL, 0, &ThreadFunc, (void*)(INT_PTR)i, CREATE_SUSPENDED, &threadID); } DWORD dwBegin = ::timeGetTime(); for(int i = 0; i < nCount; ++i) { ::ResumeThread(aHandle[i]); } ::WaitForMultipleObjects(nCount, &aHandle[0], true, INFINITE); DWORD dwEnd = ::timeGetTime(); _tprintf(_T("# %dms\n"), dwEnd - dwBegin); for(int i = 0; i < nCount; ++i) { ::CloseHandle(aHandle[i]); } delete[] aHandle; ::timeEndPeriod(1); return 0; }
ペアリング版
#include <stdio.h> #include <windows.h> #include <process.h> #include <tchar.h> #include <mmsystem.h> #pragma comment(lib, "winmm.lib") static const int TIMES = 0x20000000; unsigned int CALLBACK ThreadFunc(void* v) { int id = (int)(INT_PTR)v; int a = 10; int b = 20; DWORD dwBegin = ::timeGetTime(); __asm { mov eax, a ; mov edx, b ; mov ecx, TIMES ; カウンタ変数 _LOOP: ; ↓すごくペアリングしてる(ハズ) - ってか何もしてn(ry mov esi, eax ; a mov edi, edx ; a' xor esi, esi ; b xor edi, edi ; b' mov esi, eax ; c mov edi, edx ; c' mov eax, esi ; d mov edx, edi ; d' loop _LOOP; } DWORD dwEnd = ::timeGetTime(); printf("%d - %dms \n", id, dwEnd - dwBegin); return 0; } int _tmain(int arcv, TCHAR* argv[]) { ::timeBeginPeriod(1); int nCount = _ttoi(argv[1]); HANDLE* aHandle = new HANDLE[nCount]; for(int i = 0; i < nCount; ++i) { unsigned int threadID = 0; aHandle[i] = (HANDLE)_beginthreadex(NULL, 0, &ThreadFunc, (void*)(INT_PTR)i, CREATE_SUSPENDED, &threadID); } DWORD dwBegin = ::timeGetTime(); for(int i = 0; i < nCount; ++i) { ::ResumeThread(aHandle[i]); } ::WaitForMultipleObjects(nCount, &aHandle[0], true, INFINITE); DWORD dwEnd = ::timeGetTime(); _tprintf(_T("# %dms\n"), dwEnd - dwBegin); for(int i = 0; i < nCount; ++i) { ::CloseHandle(aHandle[i]); } delete[] aHandle; ::timeEndPeriod(1); return 0; }
テスト内容
1〜8スレッド x 10回実行し、処理時間の平均値を算出し「非ペアリング - ペアリング」の差(非ペアリングがどれだけ遅いか)を算出してみました
結果
| スレッド数→ | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
|---|---|---|---|---|---|---|---|---|
| Athlon 64 x2 4400+ - 非pair | 1441.5 | 1464.3 | 2191.1 | 2909.1 | 3633.1 | 4329.8 | 5066.4 | 5749.7 |
| Athlon 64 x2 4400+ - pair | 1444.4 | 1470.6 | 2201.3 | 2926.2 | 3642.7 | 4365.9 | 5051.1 | 5756.6 |
| Athlon XP 1500+ - 非pair | 2600.1 | 5176.1 | 7756 | 10340.3 | 12914.6 | 15488.5 | 18061 | 20649.5 |
| Athlon XP 1500+ - pair | 2599 | 5178.7 | 7772.5 | 10348.3 | 12914 | 15490 | 18064.2 | 20637.4 |
| atom 330 - 非pair | 4747.3 | 5474.5 | 6382 | 7295.8 | 9847.8 | 10908.4 | 13107 | 14644.1 |
| atom 330 - pair | 4061.3 | 4795.8 | 5761.2 | 6804.5 | 9126.4 | 10225.3 | 12092.5 | 13588.8 |
| 差 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| Athlon 64 x2 4400+ - 差 | -2.9 | -6.3 | -10.2 | -17.1 | -9.6 | -36.1 | 15.3 | -6.9 |
| Athlon XP 1500+ - 差 | 1.1 | -2.6 | -16.5 | -8 | 0.6 | -1.5 | -3.2 | 12.1 |
| atom 330 - 差 | 686 | 678.7 | 620.8 | 491.3 | 721.4 | 683.1 | 1014.5 | 1055.3 |
(単位:ms)
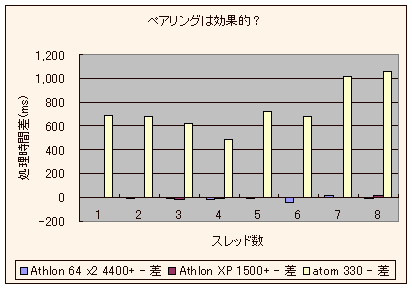
うん、実にまんま!
アウトオブオーダーが実装されている Athlon系では計測誤差程度しか差が出ていません。(IntelのCPUも当然実装されてます*1)こりゃ賢い。
そして、インオーダープロセッサの ATOM君は、こんなへたれコードでもモロに影響が出て見事に差が出てますね。まさに 計画通り! の結果です。
そして面白いのは、それでも4スレッド目が一番差が少ないことでしょうか。
「ペアリングが出来ていない -> パイプラインがガラ空き -> ハイパースレッディングで処理詰め込んじゃおうぜ!」
ってのが見事に効いているのだと思われます。すばらしい!
…と、解釈したんですが、間違ってないよなぁ…(ぉ ^^;